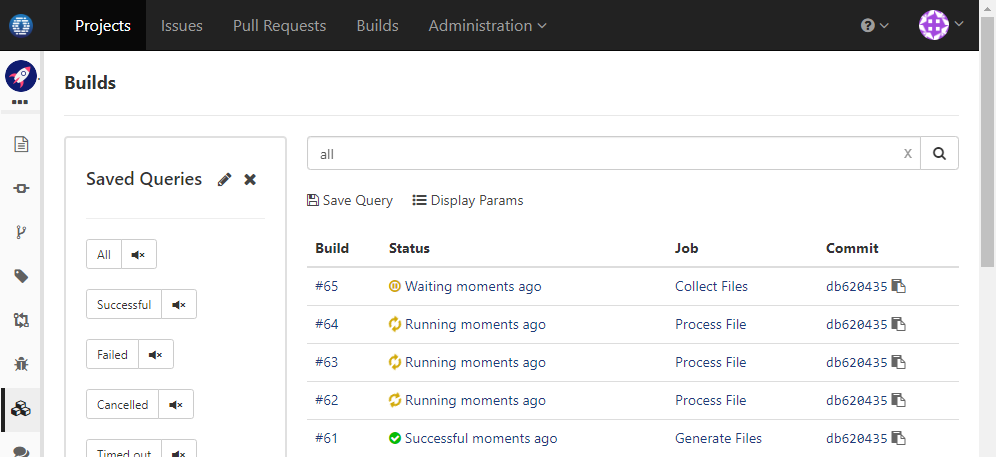
Job Dispatch and Aggregation
This tutorial explains how to dispatch jobs to execute concurrently and aggregate results in the end.
Assumed Scenario
Generate files in one job, process each file concurrently in the second job, and collect processed results in the third job
How to Set Up
-
Define a groovy script to get list of published artifact names from upstream build whose number is passed via parameter upstream-build-number:
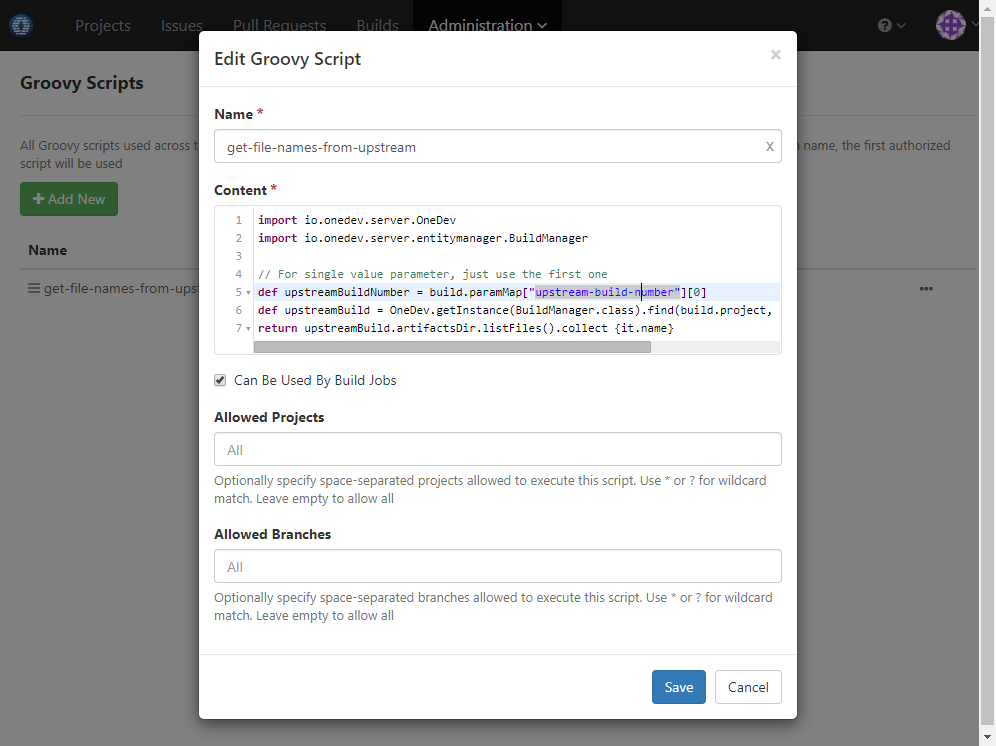
Content of the script:
import io.onedev.server.OneDev
import io.onedev.server.entitymanager.BuildManager
// Variable "build" represents the build being triggered currently
// For single value parameter, just use the first one
def upstreamBuildNumber = build.paramMap["upstream-build-number"][0]
def upstreamBuild = OneDev.getInstance(BuildManager.class).find(build.project, upstreamBuildNumber as Long)
return upstreamBuild.artifactsDir.listFiles().collect {it.name} -
Edit build spec to add job Generate Files with below command:
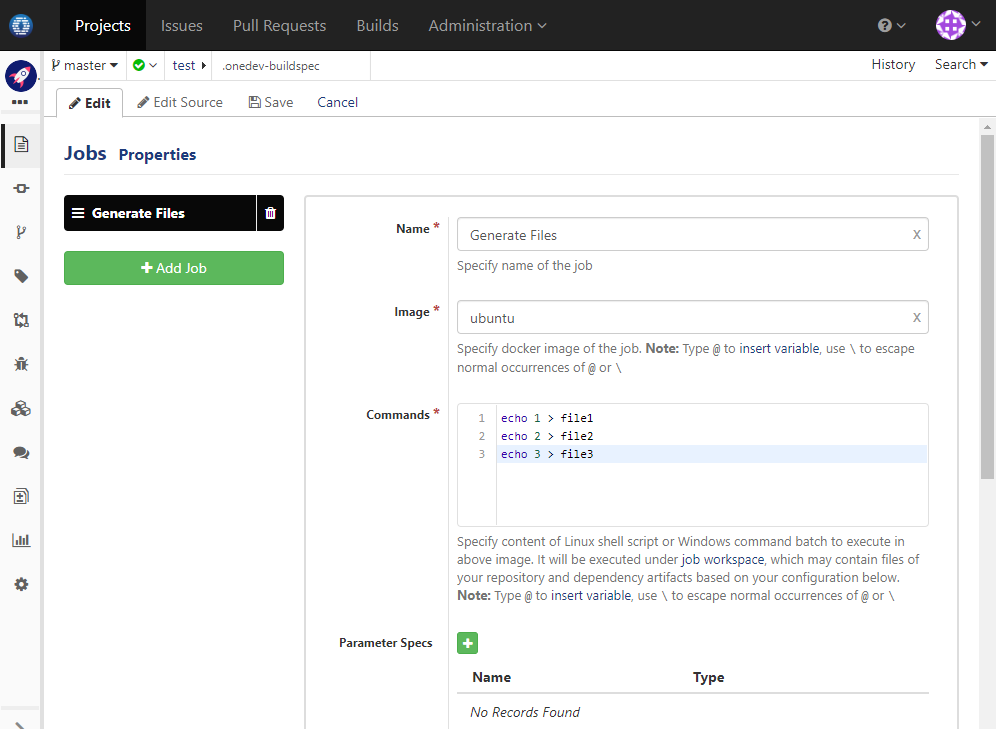
Command to generate files:
echo 1 > file1
echo 2 > file2
echo 3 > file3
-
Continue to edit job Generate Files. In Artifacts & Reports section, publish generated files:
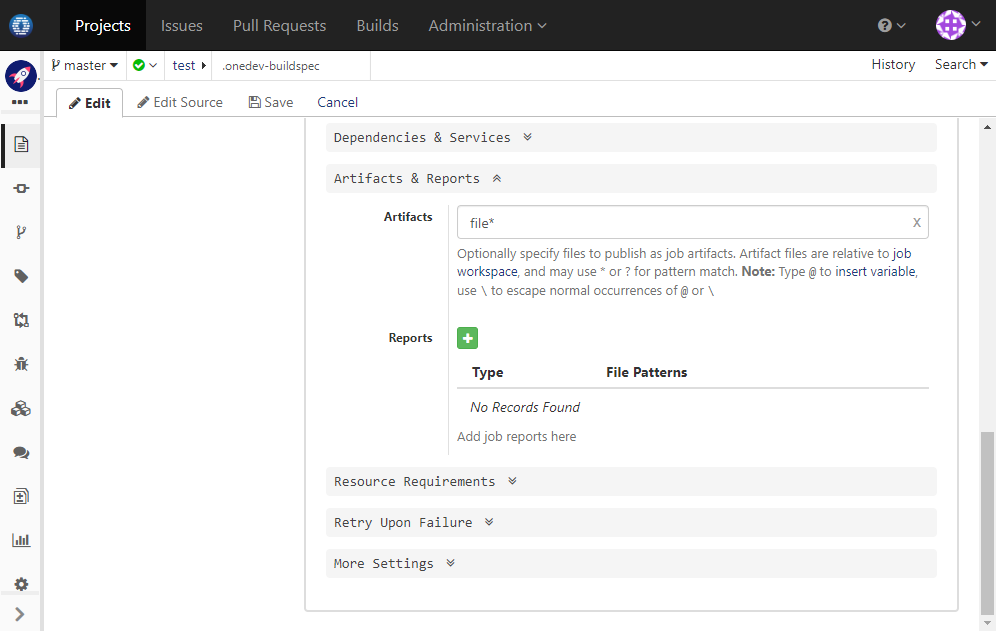
-
Add job Process File with parameter file which will be used to hold name of the file being processed
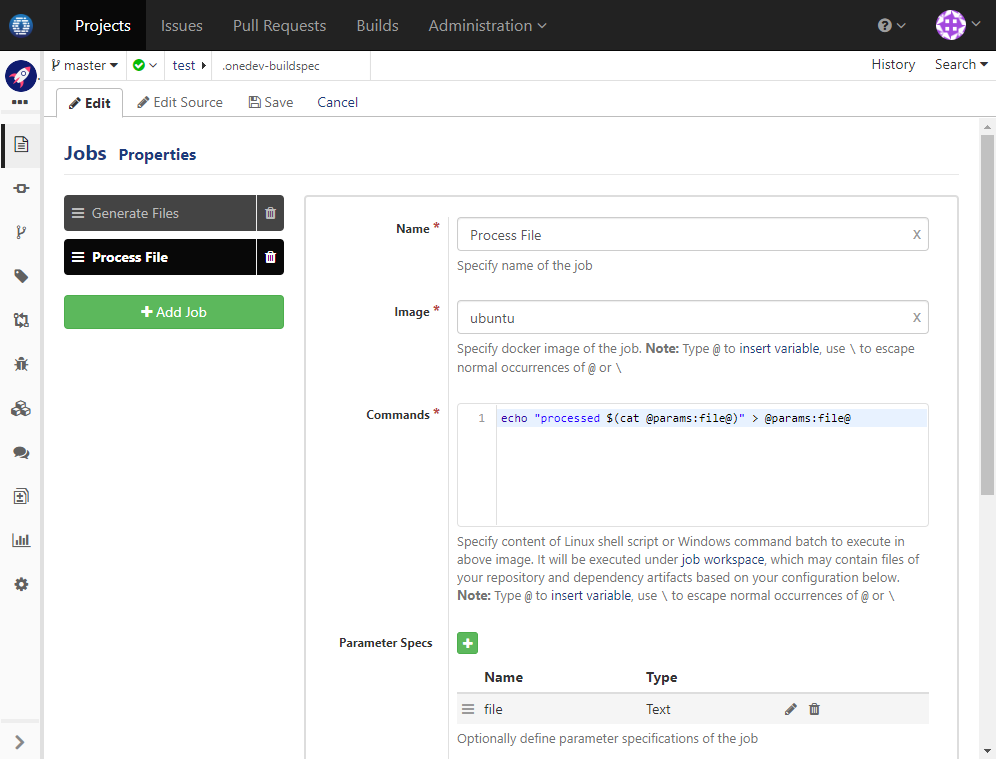
For demonstration purpose, the command prepend message processed to the file content:
echo "processed $(cat @params:file@)" > @params:file@
-
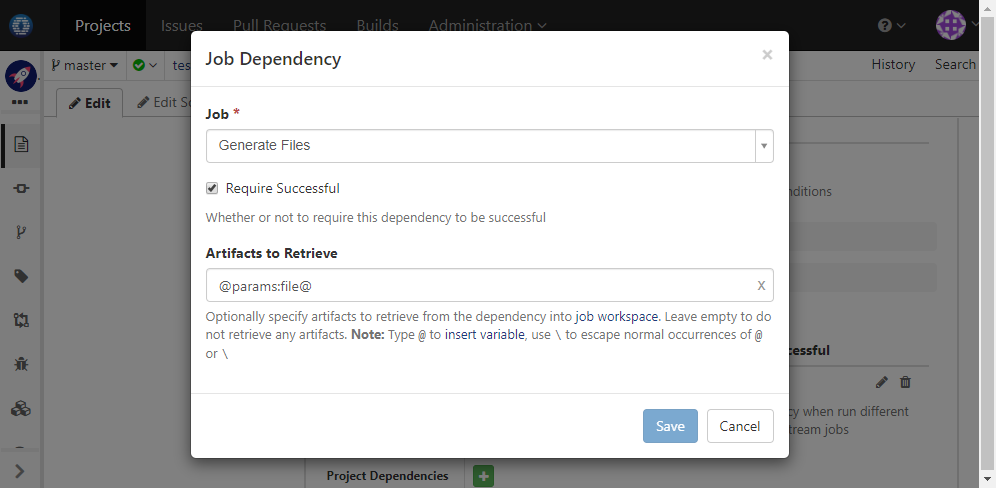
Continue to edit job Process File. In Dependencies & Services section, add a job dependency to retrieve published file with name equal to parameter file:
-
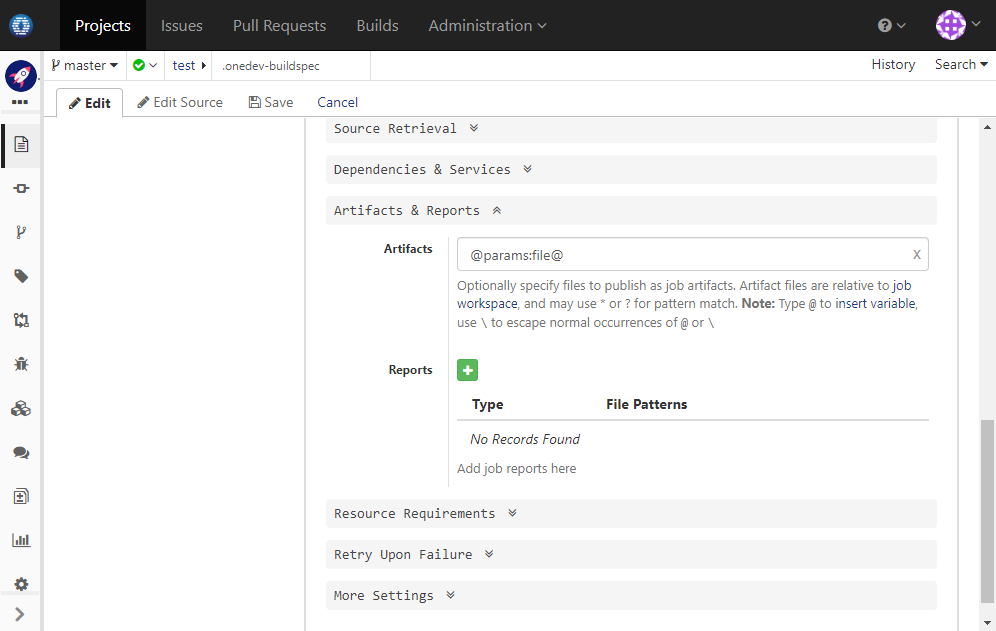
Continue to edit job Process File. In Artifacts & Reports section, publish processed file:
-
Add job Collect Files with parameter upstream-build-number which will be used to hold number of the build generating files
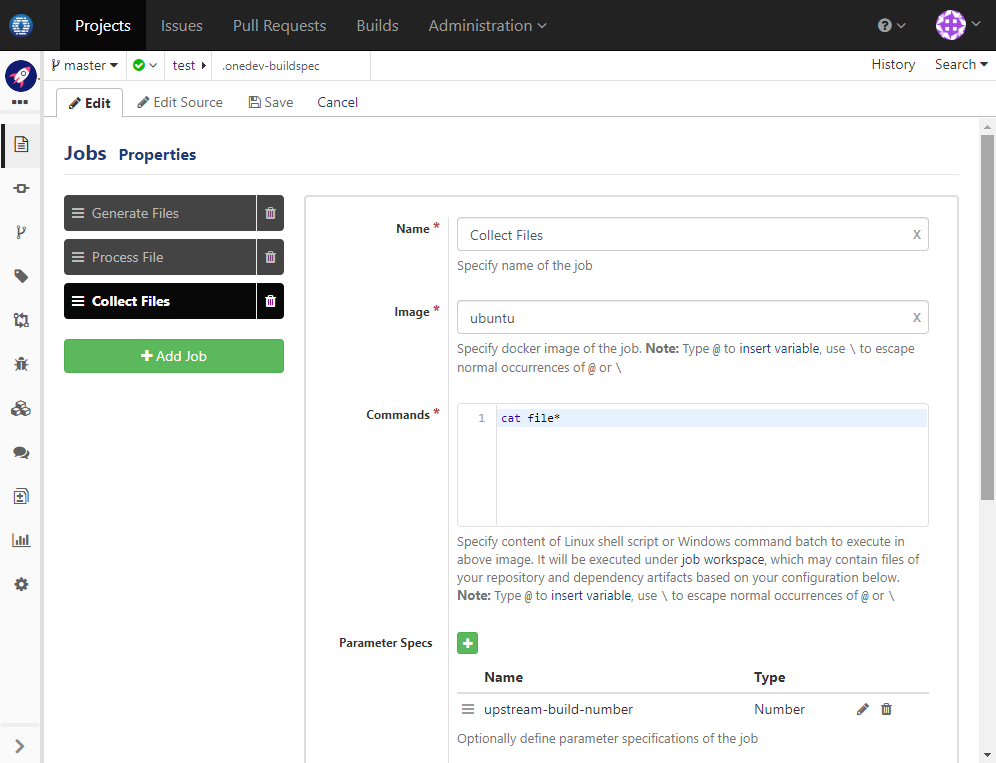
The command cat files* simply prints contents of all collected files
-
Continue to edit job Collect Files. In Dependencies & Services section, add a job dependency to Process File with param file set to evaluated result of the groovy script we added in the first step. For each of the name returned from the script, the job will be triggered once and the processed file will be collected back:
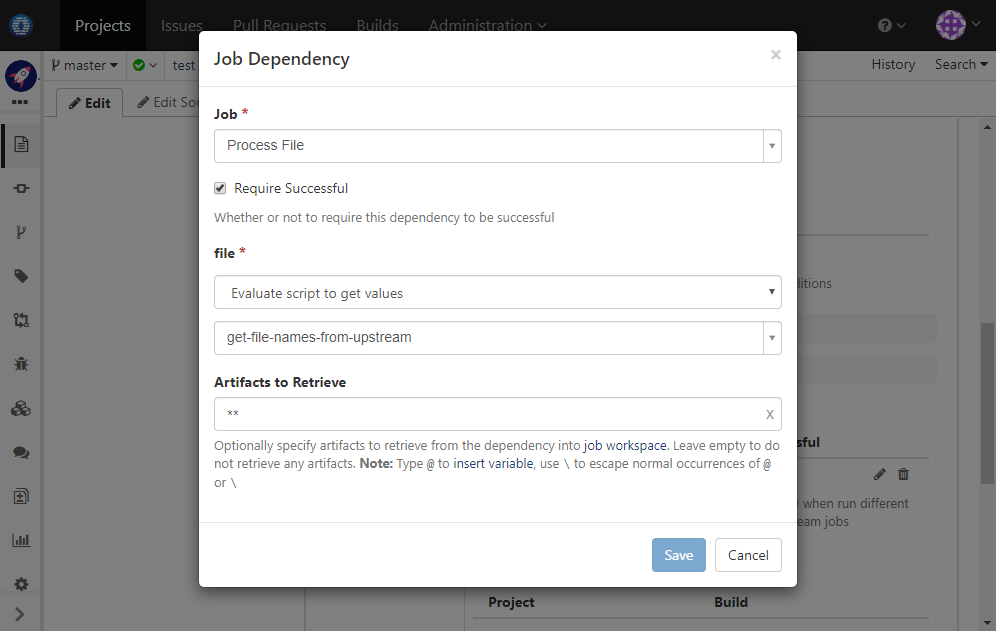
-
Go back to edit job Generate Files. In More Settings section, add a post-action to trigger job Collect Files, with param upstream-build-number set to number of current build:
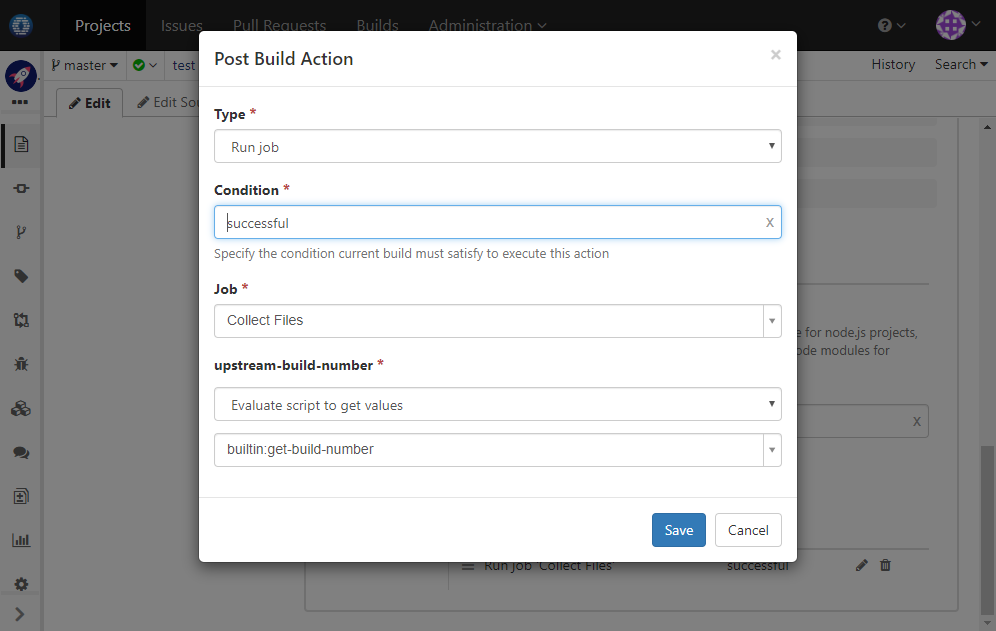
-
Done! Now run job Generate Files. After it succeeds, three builds of job Process File will run to process generated files. After all files are processed, job Collect Files will be running to collect the results